研究テーマ
情報検索、自然言語処理、電子図書館
(1) ユーザ適応型情報検索、推薦システム

Webページ
Web検索エンジンは、WWW上の情報を検索するための有用な手段である。
しかし、同じ検索語が異なるユーザによって入力されたとしても、
どのユーザが検索語を入力したかに関わらず、同じ結果を提示する
という問題点がある。一般に、各ユーザは自分の検索語に対して、
異なる検索要求を持つと考えられる。そこで、各ユーザの検索要求に
応じて、検索結果を適応させるための手法について研究している。

学術論文
また、世の中で新たに生成される知識のほとんんどは、電子的な媒体で取得され、
電子図書館システムにおいて格納されるのが一般的になっている。しかし、こうした
傾向は情報洪水の原因となり、ユーザは、検索語に一致するが、自分の情報要求に
ほとんど適合しない出版物の数に圧倒されることになる。そこで、
研究者の情報要求に適合する学術論文を推薦するための手法について
研究している。

携帯アプリ
ユーザは、アプリ・ストアを通じて、非常に数多くの携帯アプリにアクセスすることができる。さらに、
新たな携帯アプリは、日々公認され、公開されているので、アプリ・ストアで選ぶことのできる数は、
急速に増え続けている。この増加によって、ユーザは無数のユニークで、有用なアプリの提供を
受けることができる一方、自分の興味に適合するアプリを見つけることが、ますます難しく
なっている。この問題を解決するために、アプリ・ストアにおける正式なユーザの評価に
先行するツイッターの情報、ならびに、アプリに特有なバージョン情報を用いた携帯アプリの
推薦システムについて研究している。本研究課題では、グラフに基いた手法を用いて、意外性のある
アプリを推薦するシステムについても研究している。
[主な発表文献]
Webページ
- 杉山一成: ``スパース性を解消した単語ベースの協調フィルタリングに基づく適応的Web情報検索'',
人工知能学会研究会資料 SIG-FPAI-A702,pp.7-12, 2007年11月. [pdf]
- 杉山一成, 波多野賢治, 吉川正俊, 植村俊亮: ``ユーザからの負担なく構築したプロファイルに基づく適応的Web情報検索'', 電子情報通信学会論文誌, Vol.J87-D-I, No.11, pp.975-990, 2004年11月. [pdf]
学術論文
- Kazunari Sugiyama and Min-Yen Kan: ``A Comprehensive Evaluation of Scholarly Paper Recommendation Using Potential Citation Papers,'' International Journal on Digital Libraries, Springer, Vol. 16, Issue 2, pp.91-109, June 2015.
- Kazunari Sugiyama and Min-Yen Kan: ``Towards Higher Relevance and Serendipity in Scholarly Paper Recommendation'' with Martin Vesely as coordinator,
ACM SIGWEB Newsletter, Winter, Article No. 4, 2015. [pdf]
携帯アプリ
- Jovian Lin, Kazunari Sugiyama, Min-Yen Kan, and Tat-Seng Chua:
``Scrutinizing Mobile App Recommendation: Identifying Important App-related Indicators,''
The 12th Asia Information Retrieval Societies Conference (AIRS 2016),
Lecture Notes in Computer Science (LNCS), Springer-Verlag, Vol.9994, pp.197-211,
Beijing, China, November 30-December 2, 2016. [pdf]
(2) 文書の特徴付け手法

ベクトル空間法に基づいた情報検索システムや文書の分類・クラスタリングなどの
研究においては、しばしばTF-IDF法によって文書が特徴付けられる。しかし、
TF-IDF法は、その文書を特徴付ける単語に必ずしも高いスコアが割り当てられる
とは限らない。また、Webページのようなハイパーリンク構造を有する文書に
対しては、対象ページの内容だけではなく、その隣接ページの内容を用いて
特徴付けをするべきであると考えられる。そこで、
(a) 単語の頻度情報とともに、それ以外の文書内における単語の情報を用いて文書を特徴付けるための手法、
(b) ハイパーリンクで結ばれた隣接ページの内容を利用することで、
Webページ向けにTF-IDF法を改良するための手法、
について研究している。
[主な発表文献]
- Kazunari Sugiyama, Kenji Hatano, Masatoshi Yoshikawa and Shunsuke Uemura: ``Improvement in TF-IDF Scheme for Web Pages based on the Contents of Their Hyperlinked Neighboring Pages'', Systems and Computers in Japan, Vol.36, No.14, pp.56-68, February 2005. [pdf]
- 杉山一成, 波多野賢治, 吉川正俊, 植村俊亮: ``ハイパリンクで結ばれた隣接ページの内容に基づくWebページのためのTF-IDF法の改良'', 電子情報通信学会論文誌, Vol.J87-D-I, No.2, pp.113-125, 2004年2月. [pdf]
(3) Web検索結果における人名の曖昧性解消
Web検索エンジンで人物を検索した場合、その検索結果には同姓同名人物に
関するWebページが含まれる。例えば、``William Cohen''という人名で検索した
場合、この名前を有する情報科学の教授、政治家、外科医などの人物が検索結果中に
混在している。この問題に対し、各人物の実体ごとに検索結果を精度良く
クラスタリングするための手法について研究している。
[主な発表文献]
- 杉山一成, 奥村学: ``半教師有りクラスタリングを用いたWeb検索結果における人名の曖昧性解消'', 言語処理学会論文誌 自然言語処理, Vol.16, No.5, pp.23-49, 2009年10月.
[pdf]
- Kazunari Sugiyama, Manabu Okumura: ``Personal Name
Disambiguation in Web Search Results Based on a Semi-Supervised
Clustering Approach'',
The 10th International Conference on Asian
Digital Libraries (ICADL'07), Lecture Notes in Computer
Science (LNCS), Springer-Verlag, Vol.4822, pp.250-256, Hanoi, Vietnam, December 10-13,
2007. [pdf]
(4) 日本語コーパスにおける語義の曖昧性解消
単語の用例をクラスタリングする場合,(a) 教師用例として,
語義タグ付きの単語の用例を使用することができる,
(b) 語義タグ付きの用例の周りに集められた単語の用例は同じ意味を
持ち得るので,その集められた単語の用例から計算される素性を利用すれば,
教師有り語義曖昧性解消の精度を高められると期待される,
という考えに基づき,語義タグ付きの用例を導入し,
半教師有りクラスタリングを適用した,教師有り語義曖昧性解消の
手法について研究している.
[主な発表文献]
- Kazunari Sugiyama, Manabu Okumura: ``Semi-supervised Clustering
for Word Instances and Its Effect on Word Sense Disambiguation'',
The 10th International Conference on Intelligent Text Processing
and Computational Linguistics (CICLing 2009), Lecture Notes in Computer Science (LNCS), Springer-Verlag,
Vol.5449, pp.266-279, Mexico City, Mexico, March 1-7, 2009. [pdf]
- 杉山一成,奥村学:
``単語の用例の半教師有りクラスタリング'',
情報処理学会研究報告, Vol.2008, No.33, 2008-NL-184 (2),pp.7-12, 2008年3月. [pdf]
(5) 生物学文献からの情報抽出
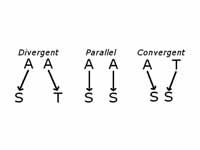
生物学などの生命科学分野においては、タンパク質同士、あるいはタンパク質と
生体分子の相互作用に関して、論文中に表現されている知識が積極的に利用されている。
しかし、多数の論文からタンパク質の相互関係を認識し、新たな知識として体系化
するには、相当な労力を必要とする。そこで、生物学の研究を支援するために、
機械学習の手法を用いて、生物学文献からタンパク質相互作用について述べている文を
同定するための方法について研究している。
[主な発表文献]
- Kazunari Sugiyama, Kenji Hatano, Masatoshi Yoshikawa and Shunsuke Uemura: ``Extracting Information on Protein-Protein Interactions from Biological Literature Based on Machine Learning Approaches'', The 14th International Conference on Genome Informatics (GIW2003), Genome Informatics, Vol.14, pp.699-700, Universal Academy Press, Yokohama, Japan, December 14-17, 2003. [pdf]